
基本概念
Prometheus 是一个开源的监控方案, CNCF 的毕业项目, 云原生监控的事实标准. Prometheus 以时间序列数据的形式收集和存储 metrics. Metrics 信息与被称为标签的可选的键值对和记录时间一起保存.
Prometheus 的主要功能特点有
- 由
metric的名称以及 Key/Value 对标签标识的时间序列数据组成的多维数据模型 - 灵活的查询语言 PromQL
- 不依赖分布式存储; 单服务节点自治能力
- 服务端通过 HTTP 协议拉取获得的时间序列数据
- 支持通过中间网关推送时间序列数据
- 通过服务发现或静态配置文件发现监控目标
- 支持多种类型的图表和仪表盘
Prometheus 以拉取的模式获取获取监控数据, 而不是由业务方向监控服务器推送. 这对于被监控的业务来说, 极大的减少了监控部分在系统中的耦合. 通常, 业务暴露出一个 HTTP 端口以暴露数据, 供 Prometheus server 抓取即可.
Metric
一般来说, Metric 是数值形式的标量单位, 它是与时间一起被记录的时间序列. 在不同应用中用户期望记录不同的 Metric. Web server 可能要希望请求数和一些指标信息, 数据库可能希望记录活跃连接数和活跃查询数之类的.
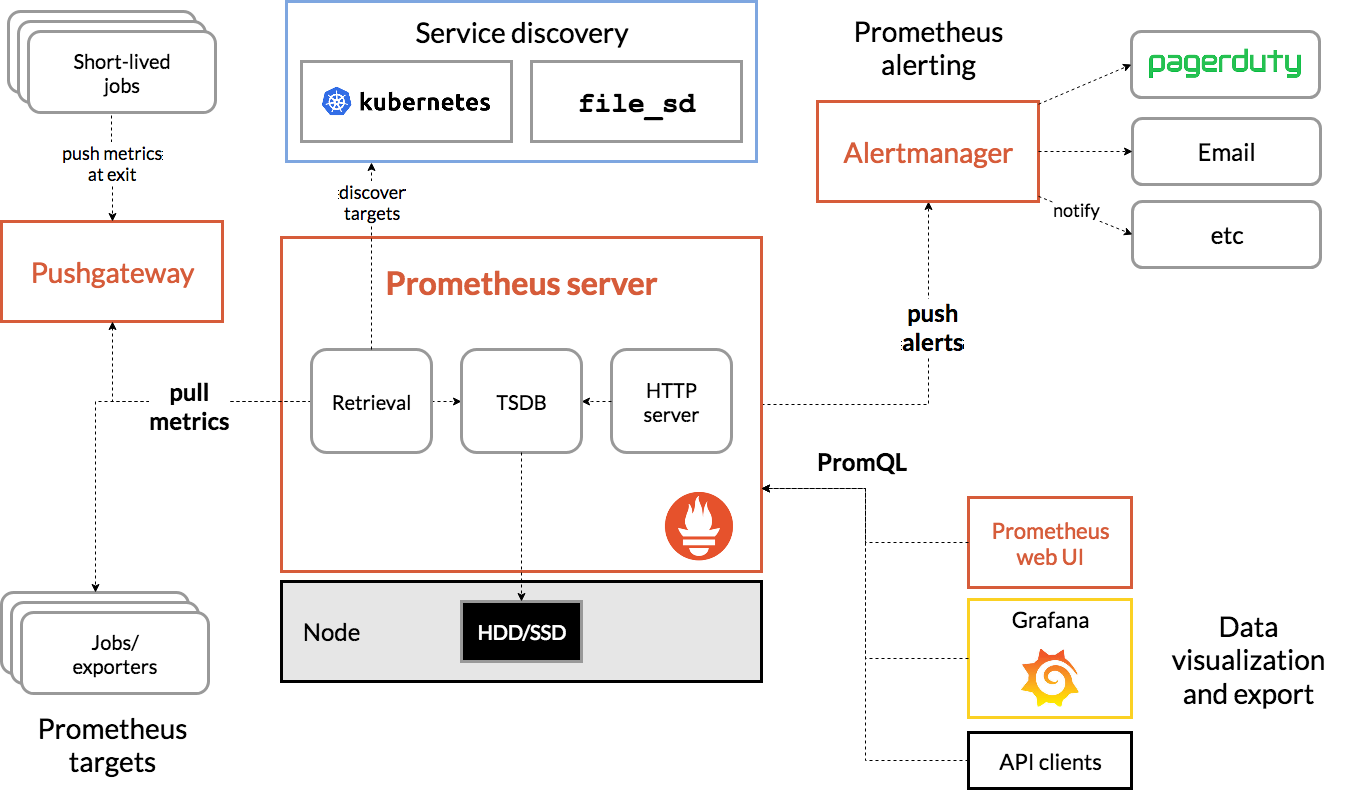
系统架构
- 主要的 Prometheus server 收集和存储时间序列数据
- 客户端库 用以监测应用程序代码
- push gateway 用以支持短期运行的任务
- 用以监控 HAProxy, StatsD, Graphite 等常用服务的 exporters
- 用以处理告警的 alertmanager
- 其他各种支持工具
适用场景
Prometheus 适合记录任何纯数值的时间序列。它既适合以机器为中心的监控, 也适合监控高度动态的面向服务的体系结构. 它对多维数据收集和查询的支持在微服务的场景中拥有特别的优势.
Prometheus 基于可靠性设计, 以保证在出现问题时可以快速进行问题诊断. 每个 Prometheus server 都是独立的, 不依赖于网络存储或其他远程服务. 当基础设施的其他部分出现故障时, 这种架构非常可靠, 另一方面, 它不需要配置大量的基础设施.
Prometheus 不适合需要 100% 的准确性的场景, 例如记录单个的计费请求, 收集的数据可能不够详细和完整. 在这种情况下应使用其他系统来收集和分析计费数据, 使用 Prometheus 进行其余的监控.
这里说的比较笼统, 从构建系统可观测性的监控来说, 我们有 Metrics , Tracing 和 Logging. 它们有各自的特点, Metrics 的特点是可聚合的, 它们是组成一个量计, 计数器或者直方图的最小单位. Logging 处理一系列离散事件. 而 Tracing 处理整个请求范围内的信息, 数据或元数据应当绑定到系统中单个事务对象的生命周期中.
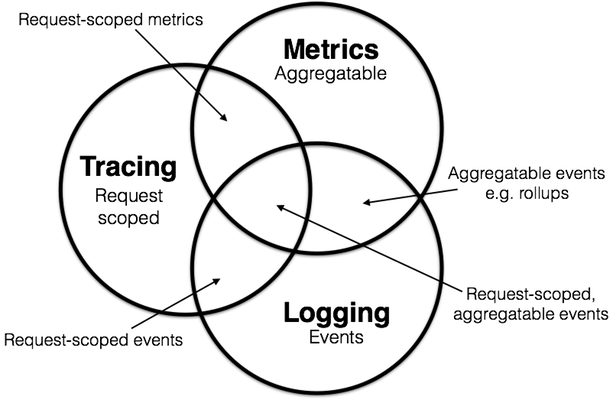
Prometheus 是个典型的 Metrics 系统, 它为系统打点, 追踪系统整体的运行情况. 比如, 记录 Web 系统中的所有请求的 HTTP 状态码, 当一段时间中 500 错误大量出现时, 可以通过配置的聚合和趋势分析发现问题并提供告警, 但它没有记录具体的请求内容, 想要复现错误的请求, 则需要 Tracing 和 Logging 系统进行进一步的诊断.
快速入门
数据模型
Metric and Label
Prometheus 在底层将所有属于同一指标名称, 同一标签集合的, 有时间戳标记的数据流存储为时间序列数据.
数据模型的表示方式为
|
|
且有以下规则
metric name
匹配正则 [a-zA-Z_:][a-zA-Z0-9_:]*, 其中 : 是用户自定义记录规则的标记, 不应该用在业务暴露的指标中
label name
匹配正则 [a-zA-Z_][a-zA-Z0-9_]*, 其中以 __ 开头的是系统保留命名
Sample
Sample 的 value 总是为一个 float64 值
以关系型数据库来类比, metric_name 相当于表名, label_name 相当于列名, label_value 相当某一字段的值, 而 metric_value 和 timestamp 的列是系统自动生成的.
比如如下名为 api_http_requests_total 指标表示了 API 所有的 HTTP 请求数, 其中标签 method 指定了方法, handler 指定了路径, 分别为 method="POST" 和 handler="/messages", 此样本的值为 11
|
|
|
|
Metric
Prometheus 提供了以下一些类型 metrics 类型
Counter
Counter 类型代表一种样本数据单调递增的指标, 即除非监控系统发生了重置, 只增不减.
例子: 系统接受的请求数, 系统错误数, 系统 uptime
Gauge
Gauge 类型代表一种样本数据可以任意变化的指标, 即可增可减.
例子: 当前实例线程数, 当前系统负载
Histogram 和 Summary
Histogram 和 Summary 用以对数据进行采样并储存其分布情况. 不同的是, Histogram 指定其配置的区间, 而 Summary 配置其分位数.
举一个具体的例子, 假设需要统计某个 WEB 页面的响应时间, 使用 Histogram 时, 需要配置其响应时间区间, <10ms, 10ms-100ms, 100ms-1000ms, >1000ms, 返回的数据如下
|
|
使用 Summary 时, 则配置 0.5, 0.9, 0.99, 代表了其50分位, 即中位数, 90分位, 99分位的值
|
|
此时可以看到, 这个 HTTP 接口一共接受了 216 次请求, 一共耗时使用了 2.88s, Histogram 展示了具体数值分布, 123 个在 10ms 内, 有 216 - 215 = 1 个请求耗时超过了 1000ms. Summary 展示了分布的百分位, 中位数是 0.012s, 99分位是 0.017s.
通常我们使用 Histogram 即可, Summary 会使用较多的内存构造一个滑动窗口来做统计.
注意事项
每个键值标签对的唯一组合都代表一个新的时间序列, 这会显著增加暴露的指标数和存储的数据量. 不要使用标签存储具有高基数, 即拥有许多不同的标签值的维度, 例如用户id, restful 的实际路径参数等.
|
|
在 Prometheus 中, Metric 和 Label 的命名应该总是使用 snake_case 形式, 以便后续的处理归类分割等操作.
一个 Metric 的前缀总应该使用应用名, 可以理解为一个命名空间, 例如
- prometheus_notifications_total (Prometheus 的内部指标)
- doris_consumption_latency_seconds (doris 的消费延时)
- crawler_failure_total (爬虫的总失败数)
- crawler_request_total (爬虫的总请求数)
一个 Metric 总应该以其单位的复数形式为后缀, 并且单位应该尽量统一, 如果是一个累积的计数, 总应该使用 total
- node_memory_usage_bytes
- http_requests_total
- process_cpu_seconds_total
抓取设置
通过 Prometheus Operator 的 ServiceMonitor 对象, 可以相对便捷的, 通过不直接修改 prometheus config 的方式添加抓取目标.
|
|
上面的实例指定了一个名为 example-service-monitor 的 ServiceMonitor, 它会选择所有 svc-label-key 的值为 svc-label-value 的 Service 进行监控, 目标端口为 80, HTTP 路径为 /metrics. Service 背后可能存在超过一个的无状态的 Pod, 他们会被自动发现.
Prometheus Operator 会解析 ServiceMonitor 对象, 生成相应的抓取设置到 prometheus config.
指标选择
一般 exporter 会采集很多的指标, 比如 jvm 的运行情况, http 请求情况等等. Google 在 SRE Handbook 中提出了四个黄金信号: 延迟, 流量, 错误数, 饱和度. 实际操作中可以使用 USE 或 RED 方法作为指导, USE(Utilization, Saturation, Errors) 用于资源, RED(Rate, Errors, Duration) 用于服务.
一般的在线服务, 比如 Web 服务, 数据库等, 一般关心请求速率, 延迟和错误率, 使用 RED 方法; 一般的离线服务, 如日志处理, 消息队列等, 一般关注队列数量, 进行中的数量, 处理速度以及发生的错误, 使用 USE 方法.
Rate 速率
|
|
统计访问的 QPS
Errors 错误
|
|
统计 HTTP 状态码为 5xx 的比例
Duration 请求时间
|
|
统计平均请求时间